Political Twitter Part 4
Train the Text Classification Model
For modeling, we will use the Fastai package. Fastai has built an excellent package that uses PyTorch under the hood. Fastai makes it easy to use Transfer Learning to take advantage of the latest developments in Natural Language Processing. Using the data gathered in Part 1 we will fine-tune a text classification model that will classify tweets as either “Conservative” or “Liberal.”
Click Here for full code notebook
# import libraries
import fastai
from fastai import *
from fastai.text import *
import pandas as pd
import numpy as np
from functools import partial
import io
import os
import requests
Retrieve Data from a Google Bucket
Since all of the training is done on a Google Deep Learning VM running Debian, I have stored my data in a Google Bucket.
# get data from google bucket
!gsutil cp -r gs://msds_practicum_carey/tweets_clean_df.pkl .
Read the pickle file into a Pandas Dataframe, keep only the columns we want. The Fastai Text Classification model is expecting columns named text and label, so we rename the columns to match.
# Read in text data
tweet_df = pd.read_pickle('tweets_clean_df.pkl')
# grab only the columns we want
tweet_df = tweet_df[['tweet', 'class']]
# rename columns to match expected Fastai inputs
tweet_df.rename(columns={'tweet': 'text',
'class':'label'},
inplace=True)
# change the L and C to 1 and 0
tweet_df['label'] = np.where(tweet_df['label']=='L', 1, 0)
tweet_df
| text | label | |
|---|---|---|
| 0 | RT @aafb: Congrats to @RepOHalleran & @... | 1 |
| 1 | Great to meet the new Lake County Farm Bureau ... | 1 |
| 2 | Congratulations to @waynestcollege women's rug... | 0 |
| 3 | Great to meet with the Erickson Air Crane team... | 0 |
| 4 | Always wonderful to be part of the Back to Sch... | 1 |
| ... | ... | ... |
| 1350301 | We should be upholding the National Environmen... | 1 |
| 1350302 | If anything is to be investigated, I think we ... | 0 |
| 1350303 | TODAY: Federal judge rules in favor of House R... | 0 |
| 1350304 | In the words of an old proverb, "A hit dog wil... | 1 |
| 1350305 | The new EPA regs are pure fantasy. http://t.co... | 0 |
1350306 rows × 2 columns
Tweets with less than three words were detrimental to the language model.
For modeling, we use unprocessed tweets because the Fastai package has a built-in method for preprocessing and tagging text. The idea is to retain as much information as possible when building the language model. Removing stop-words and stemming/lemming words can remove potentially useful context from the text.
#tokenize the tweets in a new column
tweet_df['token_text'] = tweet_df.text.str.split()
# create a columsn that lists the lengths of each tweet
tweet_df['length'] = tweet_df.token_text.str.len()
# specify the minimum length tweet to keep
tweet_df = tweet_df[tweet_df.length > 3]
# keep only the columns we want
tweet_df = tweet_df[['label', 'text']]
Split the data into Training and Test Dataframes
You can split a data set easily using sample in Pandas.
I split using a 60/40 Train to Test ratio.
The split data has a slight data imbalance in favor of Liberal Tweets. We do not need to do anything to fix the imbalance, but it is something we need to keep in mind when we see how well the model generalizes to new data.
# create training DataFrame
df_train = tweet_df.sample(frac=.6, replace=False, random_state=23)
# Create test dataframe
df_test = tweet_df[~tweet_df.index.isin(df_train.index)]
# Print category counts in the training dataframe
print(df_train.groupby(by='label').count())
text
label
0 353879
1 447642
Split training set into Training and Validation Dataframes
Sklearn also has an easy to use resource for splitting data.
I will do a 70/30 split between training and validation
from sklearn.model_selection import train_test_split
# split trainign set into training and validation set
df_trn, df_val = train_test_split(df_train,
stratify = df_train['label'],
test_size=0.30,
random_state=23)
Prepare data for use in Fastai models
Fastai has methods of creating a “DataBunch” to prepare the data for use in their models.
Here I prepare the data for use in a Language Model and a Text Classification model.
Fastai preprocessing can be time-consuming, so I save the output for later use.
# Language model data
data_lm = TextLMDataBunch.from_df(train_df = df_trn,
valid_df = df_val,
path = "")
#export language model data
data_lm.save('data_lm_export.pkl')
# load lang model data
data_lm = load_data("", file="data_lm_export.pkl")
# Classifier model data
data_clas = TextClasDataBunch.from_df(path = "",
train_df = df_trn,
valid_df = df_val,
vocab = data_lm.train_ds.vocab,
bs=32)
# save class model data
data_clas.save('data_clas_export.pkl')
# load class model data
data_clas = load_data("", file="data_clas_export.pkl")
Fit a language model using Transfer Learning
Using Fastai’s pre-trained AWD_LSTM model, we can fine-tune the word embeddings to our specific data.
The idea of the language models is to be able to learn enough of the semantic meaning of the words in the provided documents to be able to predict the next words. The language model can then be used to help in the classification model. The more accurate we can make the language model, the better we can expect our classification model to perform. We should not expect to get very high accuracy; 44% was accurate enough to be useful.
# create the language model
learn = language_model_learner(data_lm,
arch = AWD_LSTM,
pretrained=True,
drop_mult=0.5)
# plot the learning rate curve
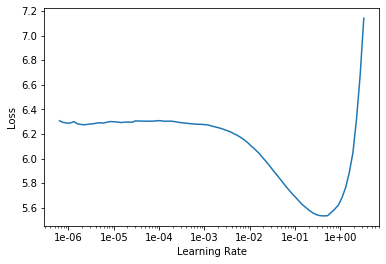
learn.lr_find()
learn.recorder.plot()
It is essential to use the correct learning rate. Fastai uses the “One Cycle Method” to fit a model. For each training epoch, the model will start at a low learning rate. By the middle of the epoch, it will reach the chosen maximum. The second half of the epoch will see the learning rate fall to slightly below the rate seen in the beginning. The theory is that the high learning rate in the middle of the cycle serves as a regularization method that prevents overfitting of the model.
# fit the language model to fine tune the embeddings
learn.fit_one_cycle(1, 6e-2)
#save encoder for use in the text classification model
learn.save_encoder('ft_enc')
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.516257 | 3.271595 | 0.442439 | 08:27 |
Fit the text classification model.
The goal of this model is to classify tweets as either “Conservative” (Category 0) or “Liberal” (Category 1)
# Create the model
learn = text_classifier_learner(data_clas,
arch=AWD_LSTM,
drop_mult=0.5)
# load the encoder created with the lang model
learn.load_encoder('ft_enc')
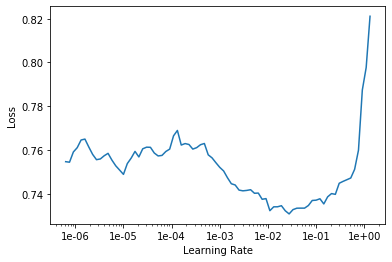
learn.lr_find()
learn.recorder.plot()
We select a learning rate that is about halfway down the curve that leads to the lowest Loss value.
Now, we fit the model.
The model is fit inside of a Deep Learning Virtual Machine running Debian Linux and outfitted with an NVIDIA Tesla V100 GPU. These training times will increase as less powerful computing methods are used.
For example, the Virtual Machine using an NVIDIA Tesla K80 instead of the heavy-duty V100 increases the training time of each epoch to over 20 minutes.
# unfreeze the pretrained weights
learn.unfreeze()
# fit the model
learn.fit_one_cycle(10, max_lr=2e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.511863 | 0.480239 | 0.756393 | 07:19 |
| 1 | 0.448711 | 0.434430 | 0.788781 | 07:10 |
| 2 | 0.399988 | 0.379893 | 0.821710 | 07:20 |
| 3 | 0.376124 | 0.374514 | 0.817186 | 07:12 |
| 4 | 0.345922 | 0.362102 | 0.830082 | 07:21 |
| 5 | 0.342125 | 0.354612 | 0.834399 | 07:08 |
| 6 | 0.331497 | 0.354680 | 0.835189 | 07:21 |
| 7 | 0.319933 | 0.354558 | 0.836694 | 07:32 |
| 8 | 0.305830 | 0.358103 | 0.838932 | 07:04 |
| 9 | 0.275868 | 0.361764 | 0.839019 | 07:15 |
After ten epochs, the validation loss has stopped decreasing. Any more training, and we will likely see the accuracy drop.
# Export the model object
learn.export("export.pkl")
Evaluate the performance of the Model
The model is ~84% accurate on the validation data. We held out 40% of our collected data to serve as a test set to see how well the model generalizes to data it has not yet seen.
Bellow, we load only the unlabeled tweets into the model for classification.
The idea of test data is that the model is not given the correct classification. We want to see how well the model performs when it lacks any knowledge.
# import the model object
learn = load_learner("", file="export.pkl")
# load unlabled test data into the learner
learn.data.add_test(df_test.text.tolist())
# get predictions on test data
preds,y = learn.get_preds(ds_type=DatasetType.Test)
Load the predictions into the test dataframe so that we can obtain the metrics.
# extract only the class prediction into a PyTorch Tensor object
scores = preds[:,1].tolist()
pred_label = preds.argmax(dim=-1)
# convert the tensor into a python list
predictions = pred_label.tolist()
# add the list as a column in the test dataframe
df_test['preds'] = predictions
Model Performance on Test Data
The model performs well on test data. It classifies with about 84% accuracy. One interesting observation is that it classifies Liberal Tweets with higher accuracy (86%) than it does conservative tweets (82%). This is likely due to the slight data imbalance in the collected dataset.
from sklearn.metrics import classification_report
# get a classification report using sklearn
print(classification_report(y_true=df_test.label,
y_pred=df_test.preds,
target_names=["Conservative", "Liberal"]))
precision recall f1-score support
Conservative 0.82 0.81 0.82 236443
Liberal 0.85 0.86 0.86 297905
accuracy 0.84 534348
macro avg 0.84 0.84 0.84 534348
weighted avg 0.84 0.84 0.84 534348
Performance on a few recent tweets
For fun, let us see how well the model performs on some very typical tweets from the President and some Candidates?
Category 0 = Conservative
Category 1 = Liberal
# Trump Tweet predicted as Conservaive
learn.predict('MAKE AMERICA GREAT AGAIN and then, KEEP AMERICA GREAT!')
(Category 0, tensor(0), tensor([0.6052, 0.3948]))
# Sanders tweet predicted as liberal
learn.predict("The world's richest 1% have over twice the wealth of \
6.9 billion people. The planet will not be secure or peaceful when so few \
have so much and so many have so little.")
(Category 1, tensor(1), tensor([0.0377, 0.9623]))
# Elizabeth Warren predicted as Liberal
learn.predict("Former Presidents & other Washington bigwigs shouldn’t be able \
to cash in on their connections with high-powered lobbying jobs. My bill to\
#EndCorruptionNow would place a lifetime ban on lobbying by fmr Presidents \
(& VPs, members of Congress, federal judges, & cabinet members).")
(Category 1, tensor(1), tensor([0.0497, 0.9503]))
# Pete Buttigieg tweet is liberal
learn.predict("Corporate greed and generations-long racist policies have \
thrown millions of Americans into a housing crisis that threatens our economy,\
health, and sense of belonging.Today, I’m proud to put forward my plan to \
build housing justice in America.")
(Category 1, tensor(1), tensor([0.0162, 0.9838]))
# Trump tweet predicted as Conservative
learn.predict("Great honor, I think? Mark Zuckerberg recently stated that \
“Donald J. Trump is Number 1 on Facebook. Number 2 is Prime Minister Modi of \
India.” Actually, I am going to India in two weeks. Looking forward to it!")
(Category 0, tensor(0), tensor([0.8821, 0.1179]))
Closing Thoughts
My assumption in the collection phase was that Republicans say conservative things, and Democrats say liberal things. Lacking a better heuristic for quickly labeling the data this assumption seems justified. The model performance validates how close that assumption is to reality. Perhaps a more accurate statement would be, “Republicans usually say Conservative things, and Democrats typically say Liberal things.”
Would you attribute this tweet to a Conservative or a Liberal:
“It has been two years since the tragedy in Parkland. We will always mourn the innocent lives taken from us – 14 wonderful students and 3 terrific educators. Earlier this week, I met with families whose experiences from that horrible day still pierce the soul.”
The model predicts at 80% that it is “Liberal.”
However, President Trump (a Conservative Republican) is the author.
The prediction is wrong, but is it useful?
I would offer that it is useful because based on the 1.3 Million tweets that went into creating the model, President Trump’s language above more closely aligns with a Liberal than a Conservative.
The potential usefulness of this model is not that it can predict the political affiliation of the author but that it can classify how far to either political spectrum the language falls.
In the second half of my project, we will explore some Software Engineering techniques that any Data Scientist can use to take their model from the notebook to production.